IA générative en entreprise : les leçons à tirer du cas Deloitte Australie
L’adoption massive de l’intelligence artificielle générative en entreprise cache une réalité inquiétante : 95 % des projets échouent. Le récent scandale Deloitte en Australie illustre parfaitement pourquoi.
IA générative : ce que l’affaire Deloitte révèle sur les risques d’un usage mal encadré
La confusion entre l’outil et le processus, cause principale des échecs en entreprise
En octobre 2025, Deloitte Australie a fait l’objet d’un examen médiatique après la remise d’un rapport contenant des erreurs attribuées à l’IA générative. Selon plusieurs sources, une partie du contrat (environ 290 000 USD) aurait été remboursée.
La raison ? Un rapport de 237 pages contenant de multiples erreurs générées par l’IA : références académiques inexistantes, jurisprudences inventées et même une fausse citation attribuée à un juge fédéral.
Le chercheur Chris Rudge (Université de Sydney) a découvert l’imposture presque par hasard :
« J’ai instantanément su que c’était soit halluciné par l’IA, soit le secret le mieux gardé au monde. »
Deloitte a reconnu avoir utilisé Azure OpenAI GPT-4o pour rédiger certaines parties du rapport sans les procédures de vérification nécessaires…
Selon Stéphane Peeters, analyste en gouvernance de l’IA :
« Le point commun de ces échecs est toujours le même : une confusion fondamentale entre l’outil et le processus. Les entreprises achètent ChatGPT ou Copilot comme elles achèteraient une imprimante, sans transformer le processus humain de validation et de responsabilité qui doit l’encadrer. »
Cette réflexion résume parfaitement le problème : l’échec n’est pas technologique, il est managérial.
Pourquoi 95 % des entreprises échouent avec l’IA générative
Une étude du MIT (2025) révèle que 95 % des projets d’IA générative ne tiennent pas leurs promesses.
En cause : une approche que nous appelons l’IA “Outside In”, que Deloitte a incarnée à la perfection.
L’IA “Outside In” : prometteuse… mais dangereuse
Cette méthode consiste à laisser les collaborateurs interroger librement l’IA pour collecter des informations externes (jurisprudence, pratiques fiscales, données sectorielles, etc.).
Le problème ?
- Les modèles de langage comme GPT-4 produisent du texte plausible, pas forcément vrai.
- L’information peut être inventée lorsqu’elle n’existe pas dans les données d’entraînement.
- Et chaque requête consomme une énergie considérable, pour un résultat non vérifiable.
C’est exactement ce qui est arrivé à Deloitte.
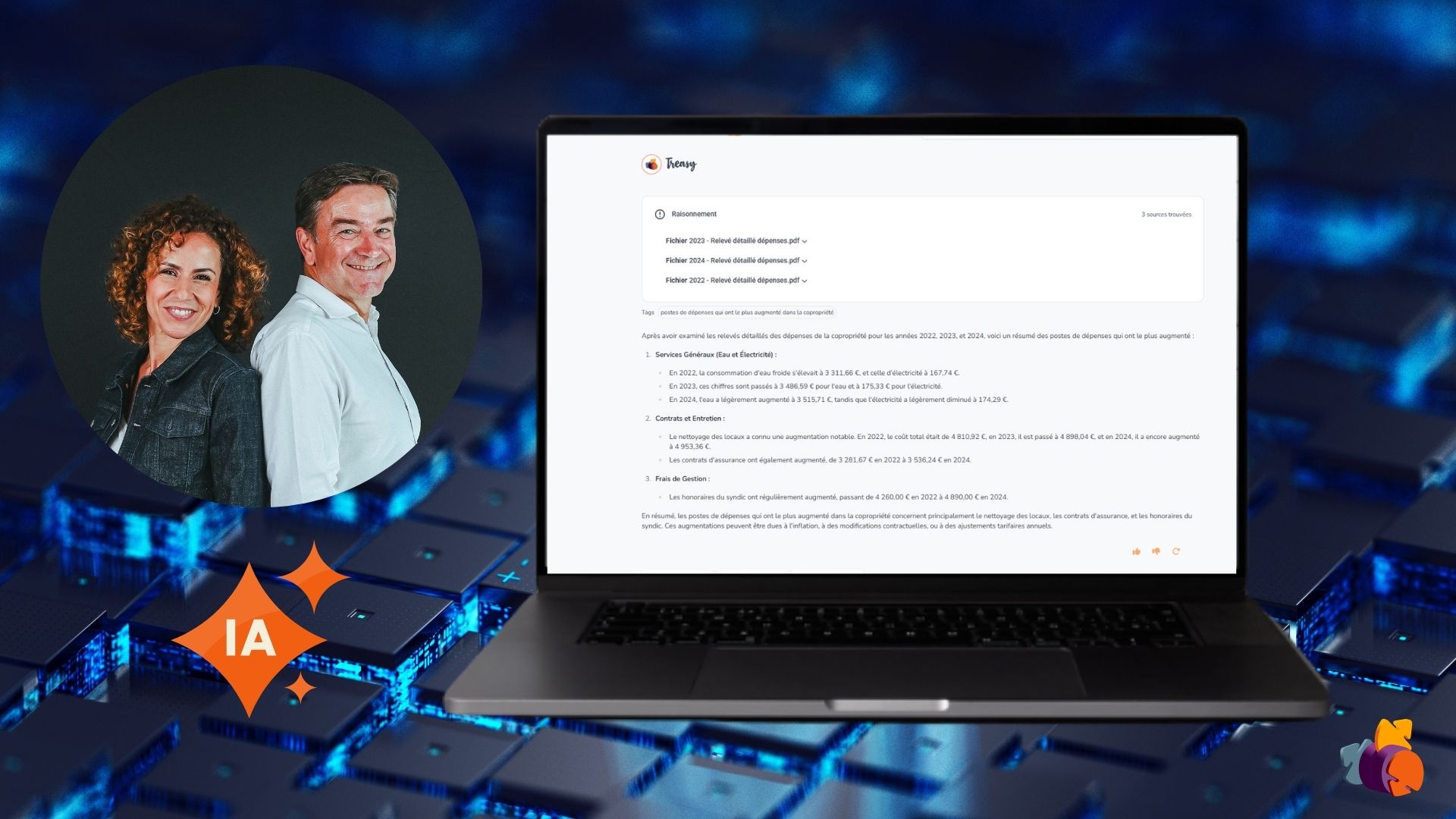
L’IA “Inside Out” : l’approche sécurisée et souveraine selon Treasy
Chez Treasy (solution française de GED intelligente), nous adoptons une approche radicalement différente :
l’IA “Inside Out”, centrée sur vos données internes et sécurisées.
Le principe : exploiter vos propres données, en toute sécurité
Contrairement à l’approche “Outside In”, notre IA ne va pas chercher sur le web :
elle analyse exclusivement vos documents internes, stockés dans une dataroom souveraine hébergée en France.
- Aucune exfiltration de données : tout reste dans votre environnement sécurisé.
- Puissance de calcul optimisée : faible empreinte énergétique.
- Résultats traçables et vérifiables : chaque réponse renvoie à la source d’origine.
Des cas d’usage concrets et maîtrisés
L’IA Treasy assiste les professionnels sur des tâches précises, sans jamais remplacer l’humain :
- Vérification automatique d’une pièce d’identité (lecture OCR)
- Extraction de données depuis un avis d’imposition
- Synthèse automatique d’un compte rendu de réunion
- Détection de pièces manquantes dans un dossier client
➡️ L’IA accélère les processus humains sans jamais les dénaturer.
Les bénéfices mesurables de l’approche “Inside Out”
- Gain de temps : jusqu’à 70 % de temps économisé sur la recherche documentaire.
- Zéro hallucination : l’IA ne génère que des contenus issus de vos propres documents.
- Conformité garantie : hébergement sur serveurs français certifiés ISO 27001.
- Traçabilité totale : chaque action est journalisée et vérifiable.
D’autres victimes de l’IA non maîtrisée
Le cas Deloitte n’est qu’un exemple. D’autres cas similaires :
- ⚖️ Avocats new-yorkais (2023) : citations inventées dans un mémoire juridique.
- ✈️ Air Canada (2024) : chatbot ayant inventé une politique de remboursement.
- 📰 CNET (2023) : 70+ articles corrigés pour erreurs factuelles.
- 🏥 Cigna (2023) : IA utilisée pour refuser 300 000 remboursements médicaux sans contrôle humain.
Les 3 principes d’une IA responsable et souveraine
- L’IA assiste, elle ne décide pas
Toujours intégrer des contrôles humains dans les décisions critiques.
- Les données restent sous contrôle
Privilégiez des solutions hébergées en France, garantissant souveraineté et sécurité.
- La vérifiabilité avant la vitesse
Un résultat rapide mais faux n’est pas conforme. L’IA doit citer ses sources.
L’IA éthique et souveraine : le choix stratégique des entreprises françaises
Chez Treasy, nous avons fait de la souveraineté numérique française un pilier de notre ADN :
- Hébergement 100 % France – serveurs certifiés ISO 27001.
- IA entraînée sur vos règles métier – sans aucune requête vers l’extérieur.
- Transparence totale – chaque action documentée et traçable.
- Conformité native – RGPD, eIDAS et standards sectoriels inclus dès la conception.
Leçons à tirer du cas de Deloitte
- Former avant de déployer – 58 % des dirigeants utilisent l’IA sans formation préalable.
- Instaurer une validation humaine – chaque output doit être contrôlé.
- Privilégier la souveraineté – aucune donnée sensible ne doit sortir de votre écosystème.
- Assumer la responsabilité humaine – l’IA aide, mais ne décide jamais seule.
Conclusion : remettre l’humain au cœur de l’intelligence artificielle
Le cas Deloitte est une leçon.
L’IA générative ne comprend pas, ne vérifie pas, ne sait pas.
Elle n’est puissante que lorsqu’elle s’intègre dans un cadre humain et souverain.
Chez Treasy, nous défendons une IA qui accélère le travail des professionnels sans compromettre la sécurité ni la qualité.
L’IA ne remplace pas votre expertise. Elle la renforce.
Découvrez comment Treasy utilise l’IA de façon responsable
Essayez gratuitement notre IA exploratrice :
FAQ
Trouvez ici les réponses simples à toutes les questions que
vous vous posez concernant Treasy
Toutes les données et tous les fichiers de nos clients sont enregistrés et protégés sur des serveurs Cloud localisés en France, plus précisément en Ile-de-France.
Treasy adopte et adoptera toujours une politique très rigoureuse de la protection de vos données.
Aucune information vous concernant, que ce soit coordonnées, fichiers, sources de collecte de ces fichiers, statistiques de fréquentation et d’usage, n’est communiquée à un quelconque tiers.
Treasy facture à ses utilisateurs un abonnement (au-delà d’une période d’essai gratuit, limitée dans le temps et en étendue de services).
Tous ces abonnements représentent notre chiffre d’affaires. Celui-ci sert à payer les investissements (en particulier technologiques) et les charges de services, tels que la fourniture de moyens d’hébergement ou de connexion aux sites des fournisseurs.
Une fois votre compte Treasy créé, vous allez souhaiter le remplir et l’organiser avec votre documentation numérique, personnelle et/ou d’affaires.
Pour cela, vous allez importer vos documents numériques dans Treasy.
Pour tous les documents qui ne sont pas susceptibles d’être collectés automatiquement par Treasy, vous téléchargerez les fichiers manuellement dans votre “Data-Room” Treasy.
Pour vous apprendre à faire cela, le plus rapidement et le plus facilement possible, nous vous proposons de regarder le mode d’emploi explicatif de cet import documentaire, sur la chaine YouTube Treasy. C’est par ici !
Si vous souhaitez avoir (enfin ?) une documentation numérique bien rangée, vous avez choisi le bon service avec Treasy !
Deux hypothèses sont possibles : soit vous savez exactement comment vous souhaitez ranger vos fichiers dans Treasy, soit vous souhaitez être guidé et adopter un modèle de classement.
Si vous avez les idées claires sur la structure de classement que vous souhaitez adopter, vous pourrez l’adopter sans problème dans Treasy. Vous pourrez personnaliser et raffiner votre classement en créant dans votre Data-room Treasy autant d’espaces et de répertoires dont vous avez besoin.
Pour vous apprendre à faire cela, le plus rapidement et le plus facilement possible, nous vous proposons de regarder les modes d’emploi explicatifs des modalités de ces créations, sur la chaine YouTube Treasy. Pour l’ajout d’un espace, c’est par ici, pour celle d’un répertoire, c’est par là.
Vous n’aurez plus alors qu’à y déplacer vos documents, le mode d’emploi à ce sujet se trouvant ici.
Si, au contraire, vous souhaitez changer vos habitudes en adoptant Treasy et voulez mettre en place une méthode de classement pour votre Data-room, Treasy est là pour vous accompagner en vous proposant des modèles de classement.
Pour vous apprendre à mettre en place un modèle, le plus rapidement et le plus facilement possible, nous vous proposons de regarder le mode d’emploi explicatif, sur la chaine YouTube Treasy. C‘est par ici.
La télécollecte est un service à valeur ajoutée proposé par Treasy qui fonctionne au moyen de “connecteurs”. Utiliser un connecteur suppose de fournir votre identifiant et votre mot de passe lors de sa première utilisation, afin qu’il établisse un accès personnel et sécurisé auprès du site internet de votre fournisseur.
Vous pouvez parfaitement décider de ne pas utiliser ce service. Dans ce cas, l’alimentation de votre Dataroom Treasy passe par le téléchargement manuel de vos fichiers depuis votre ordinateur, votre smartphone ou votre sauvegarde en ligne (drive).
Tous les autres services disponibles dans Treasy sont à votre disposition : ranger vos fichiers selon vos préférences, recourir aux services de renommage ou de compression des fichiers, partager un fichier ou un dossier avec vos proches, définir vos consignes de transmission légale en cas d’indisponibilité, etc.
Il n’est pas rare que des fichiers numériques aient des titres très étranges, voire incompréhensibles.
Ce sera vrai pour des documents que vous importerez dans Treasy, si vous ne les avez pas préalablement renommés, mais aussi parfois pour des documents télécollectés par Treasy.
Nous pensons qu’il est préférable pour vous d’avoir dans votre data-room Treasy des documents dont le titre est clair, pour vous éviter de devoir les ouvrir afin de savoir de quoi il s’agit, mais aussi pour pouvoir si besoin les retrouver plus facilement avec notre moteur de recherches.
Le fait de pouvoir les renommer dans Treasy est donc une nécessité. Vous pourrez le faire manuellement, ou utiliser les propositions de titres que Treasy vous fera.
Pour vous apprendre à renommer vos fichiers dans Treasy, le plus rapidement et le plus facilement possible, nous vous proposons de regarder le mode d’emploi explicatif, sur la chaine YouTube Treasy. C’est par ici.